
/НАЗАД
Введение в проблему
Словарь экономических терминов дает следующее определение понятия: «Корреспонденция Счетов – это метод ведения бухгалтерского учета, при котором каждая операция отражается одной и той же суммой в двух счетах: дебете одного и кредите другого». При таком строгом толковании термина, очевидно, что SAP «Корреспонденцию Счетов» не поддерживает. Принятая в модуле FI концепция Документа обладает большой гибкостью, что особенно важно при формировании автоматических проводок. Однако если мы заглянем в другие словари, то сможем найти менее строгое толкование. Например, Большой Энциклопедический словарь утверждает, что «Корреспонденция Счетов – это взаимосвязь между счетами бухгалтерского учета при регистрации хозяйственной операции способом двойной записи». При таком «облегченном» подходе задача сводится к разбиению каждого FI документа на пары корреспондирующих позиций. Этот подход был реализован в ряде получивших широкое распространение программ, наиболее известная из которых включена в российскую локализацию. Все эти программы работают в ERP системе, что влечет за собой следующие проблемы:
- значительная нагрузка на ERP сервер приложений;
- отчеты имеют фиксированный формат, каждый отчет – это отдельная АВАР программа;
- настройка правил корреспонденции требует значительных трудозатрат, поскольку основана на стандартной технике настроечных таблиц.
Решение проблемы
В настоящей статье предлагается альтернативное решение, свободное от вышеперечисленных недостатков. А именно, предлагается перенести расчет корреспонденции и всю связанную с ней отчетность в SAP BW. Действительно,
- стандартная экстракция реплицирует FI документы в BW хранилище, и основная работа по расчету корреспонденции делается в рамках обычного процесса трансформации данных, что полностью разгружает ERP сервер;
- стандартный OLAP инструментарий позволяет легко формировать отчеты практически произвольной сложности, обладающие мощными средствами навигации и фильтрации данных;
- использование технологии Business Rules Framework Plus (BRFplus) позволяет полностью отказаться от настроечных таблиц и дает дополнительный бонус в виде высокой производительности, поскольку сконфигурированные правила определения корреспонденции автоматически компилируются в исполняемый АВАР код.
Алгоритм решения
Итак, требуется, «глядя» на проведенный в модуле FI бухгалтерский документ, разобрать его на пары корреспондирующих позиций. Между прочим, типичная задача для искусственного интеллекта. Однако, мы не станем предлагать сложных и экзотических решений, а будем использовать хорошо себя зарекомендовавший простой эвристический алгоритм, состоящий из следующих 6 шагов:
- Позиции документа по дебету и кредиту группируются в две таблицы Тд и Тк;
- Формируется таблица всех потенциально возможных корреспонденций (произведение таблиц Тд и Тк);
- Каждая потенциальная корреспонденция анализируется, в результате чего ей присваивается определенный целочисленный вес (приоритет). Чем выше приоритет, тем более вероятна корреспонденция. Для расчета приоритетов могут использоваться любые поля из заголовка и позиций FI документа.
- Таблица возможных корреспонденций сортируется по убыванию приоритетов.
- Строки с наибольшими приоритетами формируют пары корреспондирующих позиций. Критерием, ограничивающим число таких пар, является общая сумма по дебету (кредиту) в документе.
- Результат сохраняется.
Сразу возникает несколько вопросов. Во-первых, что имеется в виду под словом документ в шаге 1. Ответ не столь очевиден. Часто одна хозяйственная операция приводит к автоматическому созданию нескольких FI документов. Примерами являются перемещения ТМЦ и ОС между заводами или балансовыми единицами (БЕ), оплаты открытых позиций из других БЕ, перевыставление расходов и т.д. Для такого рода операций в каждой БЕ создается отдельный FI документ, и всем созданным документам присваивается единый общий номер (поле BKPF-BVORG). Если балансовые единицы принадлежат одному юридическому лицу и мы хотим исключить 79 счет из определения корреспонденции, то необходимо группировать позиции дебетов и кредитов в шаге 1 по этому общему номеру, тем самым объединяя вместе логически связанные друг с другом первичные FI проводки.
Следующий вопрос касается интерпретации приоритетов в шаге 3. Если мы говорим, что «чем выше приоритет, тем более вероятна корреспонденции», то логично запретить отрицательные значения и интерпретировать приоритет равный 0, как запрет корреспонденции. Также следует зафиксировать некоторое максимально возможное значение приоритета (например, 1.000.000), соответствующее 100%-ой вероятности. Применение описанного выше алгоритма может привести к тому, что корреспонденция для части позиций документа останется неопределенной. Если таких документов немного, то они могут обрабатываться специальными более сложными алгоритмами (для чего может использоваться технология BAdI), либо анализироваться визуально бухгалтером, поскольку запрещенная корреспонденция в документе может свидетельствовать об ошибке, сделанной в момент проводки.
Вопрос к шагу 6: что следует сохранять? Дублирование всех полей основной и корреспондирующей позиций (уже имеющихся в базе данных) не выглядит разумным. Сохранять следует необходимый минимум информации, а именно ключевые поля (БЕ, номера документов и их позиций) и суммы. SAP BW on HANA позволяет эффективно строить OLAP отчетность на объектах соединенных операциями JOIN в композитных провайдерах и Calculation View. Тем самым, доступны абсолютно все поля из заголовков и позиций документов, что позволяет легко строить такие востребованные отчеты, как:
- оборотные ведомости по дебиторам и кредиторам с корреспонденцией счетов;
- анализ отклонений на 16 счетах в разрезе номеров материалов или основных средств, которые имеются в корреспондирующих позициях;
- анализ перевыставляемых расходов и расчетов между БЕ с исключением 79 счетов;
- разделение условных и фактических начислений расходов и доходов по корреспондирующим балансовым счетам и многие другие.
Техника Calculation View позволяет легко вводить в отчетность счета синтетического учета (например, первые 4 символа номера аналитического счета) без необходимости создания атрибутов навигации для признака 0GL_ACCOUNT, тем самым не усложняя стандартную структуру данных.
Реализация
В рамках архитектуры корпоративных хранилищ данных LSA++, разделяются уровни передачи данных (Data Propagation Layer) и витрин данных (Architected Data Mart Layer). Исходные данные финансовых документов хранятся в aDSO, принадлежащих первому уровню, результаты расчета корреспонденции должны сохраняться в aDSO, принадлежащем второму. Сам процесс расчета происходит в пользовательской программе (user routine) трансформации, связывающей эти два aDSO. Семантическое группирование позволяет разбить поток данных на пакеты таким образом, чтобы каждый документ попадал целиком в один пакет. В итоге получается, что кодирование алгоритма, описанного выше, требует менее 200 строк АВАР. Следует отметить, что этот код является абсолютно универсальным и переносимым. Механизм распараллеливания при запуске процесса переноса данных (DTP) позволяет поднять производительность в 10 и более раз, по сравнению с однопоточным выполнением, без каких-либо усилий со стороны разработчика. Звучит слишком просто, не правда ли? Где же спрятаны все сложные правила определения приоритетов для корреспондирующих позиций? В BRFplus функции, вызываемой в user routine трансформации на шаге 3 описанного выше алгоритма. Эта функция имеет два входящих параметра: анализируемые позиции по дебету и кредиту, и один исходящий – целочисленный «Приоритет» корреспонденции, как показано на Рис. 1:
Рис. 1. Параметры функции
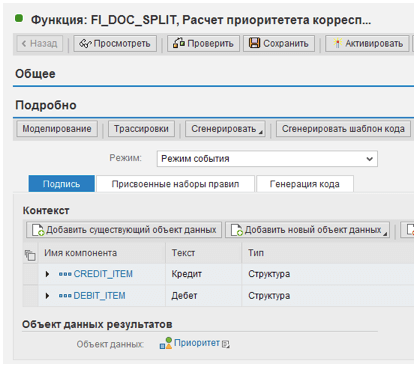
Структуры CREDIT_ITEM и DEBIT_ITEM являются идентичными и содержат все поля из позиций и заголовков первичных FI документов.Тело функции состоит из одного или нескольких наборов правил, выполняемых в определенной последовательности, как показано на Рис. 2:
Рис.2. Наборы правил, составляющие тело функции.
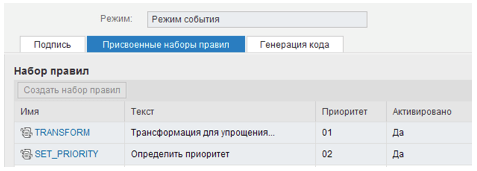
В нашем случае определены 2 набора правил:
- TRANSFORM – в котором анализируемые позиции преобразуются к определенному стандартному виду, удобному для последующего анализа (что , естественно, не влияет на позиции самого исходного документа);
- SET_PRIORITY – где определяется приоритет корреспонденции.
«Набор правил» BRFplus состоит из последовательно выполняемых «правил», каждое из которых представляет собой простую логическую конструкцию IF-THEN-ELSE.Для того, чтобы проиллюстрировать описываемую технику настроек корреспонденции, не погружаясь слишком глубоко в детали, рассмотрим простой, но показательный пример - счет-фактуру дебитора, как показано в Таблице 1:
Таблица 1. Пример документа для разбора корреспонденции.
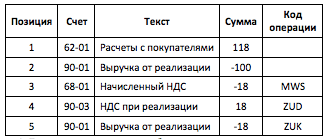
Как известно, код налога в позициях дебиторов и кредиторов проставляется только тогда, когда он уникален для документа. Мы можем стандартизовать представление удаляя код налога из этих позиций, как показано на Рис. 3:
Рис. 3. Пример правил, удаляющих код налога из позиций дебиторов и кредиторов.
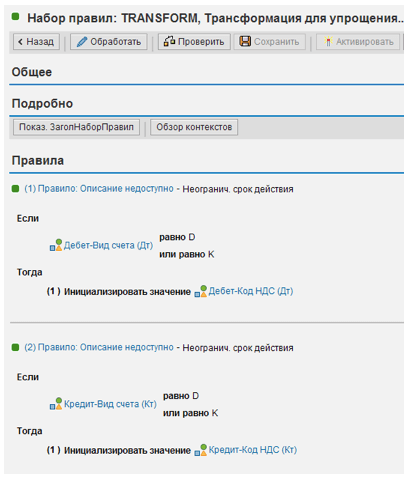
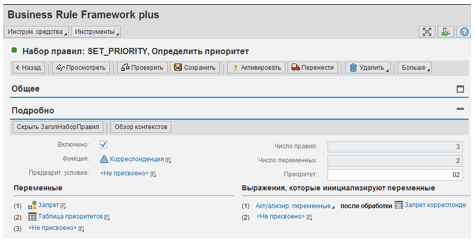
Мы определили два похожих правила для позиций по дебету и кредиту, которые инициализируют «Код НДС», если «Вид счета» = «D» или «K».Перейдем к набору правил SET_PRIORITY, рассчитывающему приоритет корреспонденции. В его заголовке мы определяем две переменные (см. Рис. 4):
- «Запрет», имеющую булев тип и инициализируемую таблицей решений «Запрет корреспонденции».
- «Таблица приоритетов», являющуюся таблицей целых чисел. Первоначально эта таблица пуста.
Рис. 4. Определение набора правил, рассчитывающего приоритет корреспонденции.
Для нашего простого примера, запрещенные корреспонденции могут быть определены в таблице решений следующего вида, как показано на Рис. 5:
Рис. 5. Таблица решений, определяющая запрещенные корреспонденции.
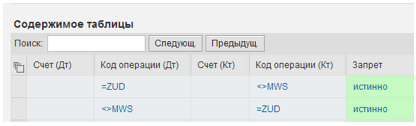
Мы запрещаем корреспонденцию счета 90-03 «НДС при реализации» со всеми счетами, кроме 68-01 «Начисленный НДС». Однако, поскольку вместо номеров счетов используются внутренние коды операций, это правило будет действовать для всех счетов-фактур, неважно продается товар или, например, объект ОС.Тело набора правил SET_PRIORITY состоит из следующих трех правил, как показано на Рис. 6:
Рис. 6. Тело набора правил, определяющего приоритет корреспонденции.
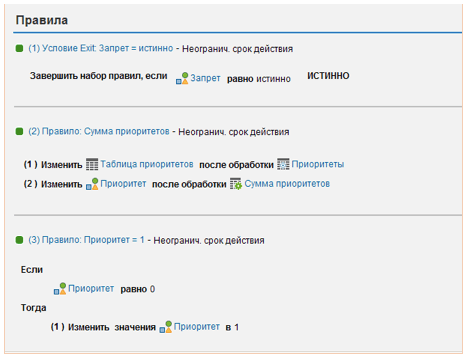
- «Запрет = истинно» – это Exit-условие завершает выполнение функции, если переменная «Запрет» имеет значение «Истинно». В этом случае приоритет корреспонденции равен 0.
- «Сумма приоритетов» – это правило состоит из 2 шагов: сначала заполняется переменная «Таблица приоритетов» на основании таблицы решений «Приоритеты», затем приоритет корреспонденции вычисляется как сумма всех строк «Таблицы приоритетов».
- «Приоритет = 1» – это правило устанавливает приоритет корреспонденции равным 1, если предыдущее правило не смогло его определить для анализируемой пары позиций.
Таблица решений «Приоритеты», для нашего примера, имеет вид, как показано на Рис. 7:
Рис. 7. Таблица решений «Приоритеты».
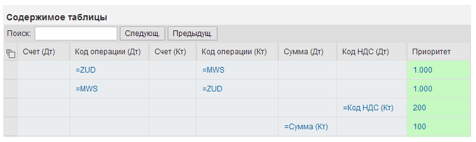
Также, как и в предыдущем примере, мы можем не задавать номера счетов. Каждая строка таблицы определяет приоритет корреспонденции, если выполняется заданное в ней условие. Рассмотрим эти условия построчно:
- Позиции с кодами ZUD и MWS получают наивысший приоритет 1000.
- Аналогично строке 1, но дебет и кредит меняются местами.
- Если «Код НДС» в обоих позициях совпадает, приоритет будет увеличен на 200. Это позволяет правильно определить корреспонденцию для документов с несколькими кодами НДС.
- Если суммы в обоих позициях совпадают, приоритет будет увеличен на 100. Это правило является общим – позиции с совпадающими суммами имеют большую вероятность корреспондировать.
Таким образом, мы определяем корреспонденцию позиций для счетов 90-03 и 68-01 с совпадающими кодами НДС как наиболее приоритетную. После чего в документе остается единственная позиция по дебету (счет 62-01) и несколько по кредиту (счет 90-01). Следовательно, дальнейшая корреспонденция определяется однозначно.
Данный пример является чисто иллюстративным. Реальные правила для определения корреспонденции являются гораздо более сложными. Однако, возможности моделирования BRFplus позволяют структурировать эти правила удобным образом, выделяя разные типы хозяйственных операций в отдельные таблицы решений, каждая из которых может иметь свой набор столбцов-условий.
Таким образом, создается функция, рассчитывающая приоритеты корреспонденции для пар позиций по дебету и кредиту. В момент первого выполнения, сконфигурированные правила компилируются в исполняемый АВАР код, что позволяет добиться наивысшей возможной производительности.
Данный пример является чисто иллюстративным. Реальные правила для определения корреспонденции являются гораздо более сложными. Однако, возможности моделирования BRFplus позволяют структурировать эти правила удобным образом, выделяя разные типы хозяйственных операций в отдельные таблицы решений, каждая из которых может иметь свой набор столбцов-условий.
Таким образом, создается функция, рассчитывающая приоритеты корреспонденции для пар позиций по дебету и кредиту. В момент первого выполнения, сконфигурированные правила компилируются в исполняемый АВАР код, что позволяет добиться наивысшей возможной производительности.
Заключение
Описанная в статье реализация OLAP отчетности по корреспонденции счетов позволяет совершить качественный рывок в этой важной теме, используя возможности SAP BW on HANA. Остается, однако, ряд вопросов, которые требуют дополнительного обсуждения:
- Данные в BW обычно загружаются периодически, что делает отчетность актуальной на конец предыдущего дня (если загрузка происходит, как обычно раз, в сутки). Если актуальность данных является критически важной, то можно использовать любую из известных технологий BW отчетности в режиме «реального времени», предлагаемых SAP.
- Описанный в статье алгоритм является эвристическим и требует тщательной настройки правил определения приоритетов корреспондирующих позиций. К сожалению, никаких «теоретических» принципов здесь нет, и процесс настройки быстро превращается в «шаманство». Однако, основным достоинством этого алгоритма является сравнительная простота и, как следствие, возможность эффективной реализации. Попытки усложнения и усовершенствования не приводят к существенным улучшениям, одновременно серьезно ухудшая производительность. Время выполнения для описанного алгоритма квадратично зависит от числа позиций в документе, что, для данной задачи, является наилучшим возможным результатом.
- Возникает вопрос можно ли реализовать описанную в статье функциональность полностью на сервере базы данных HANA без использования АВАР. Принципиальный ответ – да. Таблицы решений BRFplus могут быть транслированы в HANA артефакты при помощи Decision Service Management (DSM), представляющего собой Add-on к BRFplus. Однако, для полноценной оптимизации потребуется программирование на L, внутреннем языке БД HANA, недоступном для партнеров и клиентов SAP. Логика, легко реализуемая в АВАР коде, теряет свою гибкость и универсальность, будучи перенесена в SQLScript, при этом, конечный выигрыш в производительности отнюдь не очевиден. Однако, SAP анонсировал продолжение работ по интеграции BRFplus и HANA Rules Framework (HANA HRF), поэтому, возможно, в недалеком будущем, BRFplus будет предоставлять такие же возможности моделирования при работе с HANA, какие, в настоящий момент, имеются для АВАР сервера приложений.
/НАЗАД
Введение в проблему
Словарь экономических терминов дает следующее определение понятия: «Корреспонденция Счетов – это метод ведения бухгалтерского учета, при котором каждая операция отражается одной и той же суммой в двух счетах: дебете одного и кредите другого». При таком строгом толковании термина, очевидно, что SAP «Корреспонденцию Счетов» не поддерживает. Принятая в модуле FI концепция Документа обладает большой гибкостью, что особенно важно при формировании автоматических проводок. Однако если мы заглянем в другие словари, то сможем найти менее строгое толкование. Например, Большой Энциклопедический словарь утверждает, что «Корреспонденция Счетов – это взаимосвязь между счетами бухгалтерского учета при регистрации хозяйственной операции способом двойной записи». При таком «облегченном» подходе задача сводится к разбиению каждого FI документа на пары корреспондирующих позиций. Этот подход был реализован в ряде получивших широкое распространение программ, наиболее известная из которых включена в российскую локализацию. Все эти программы работают в ERP системе, что влечет за собой следующие проблемы:
- значительная нагрузка на ERP сервер приложений;
- отчеты имеют фиксированный формат, каждый отчет – это отдельная АВАР программа;
- настройка правил корреспонденции требует значительных трудозатрат, поскольку основана на стандартной технике настроечных таблиц.
Решение проблемы
В настоящей статье предлагается альтернативное решение, свободное от вышеперечисленных недостатков. А именно, предлагается перенести расчет корреспонденции и всю связанную с ней отчетность в SAP BW. Действительно,
- стандартная экстракция реплицирует FI документы в BW хранилище, и основная работа по расчету корреспонденции делается в рамках обычного процесса трансформации данных, что полностью разгружает ERP сервер;
- стандартный OLAP инструментарий позволяет легко формировать отчеты практически произвольной сложности, обладающие мощными средствами навигации и фильтрации данных;
- использование технологии Business Rules Framework Plus (BRFplus) позволяет полностью отказаться от настроечных таблиц и дает дополнительный бонус в виде высокой производительности, поскольку сконфигурированные правила определения корреспонденции автоматически компилируются в исполняемый АВАР код.
Алгоритм решения
Итак, требуется, «глядя» на проведенный в модуле FI бухгалтерский документ, разобрать его на пары корреспондирующих позиций. Между прочим, типичная задача для искусственного интеллекта. Однако, мы не станем предлагать сложных и экзотических решений, а будем использовать хорошо себя зарекомендовавший простой эвристический алгоритм, состоящий из следующих 6 шагов:
- Позиции документа по дебету и кредиту группируются в две таблицы Тд и Тк;
- Формируется таблица всех потенциально возможных корреспонденций (произведение таблиц Тд и Тк);
- Каждая потенциальная корреспонденция анализируется, в результате чего ей присваивается определенный целочисленный вес (приоритет). Чем выше приоритет, тем более вероятна корреспонденция. Для расчета приоритетов могут использоваться любые поля из заголовка и позиций FI документа.
- Таблица возможных корреспонденций сортируется по убыванию приоритетов.
- Строки с наибольшими приоритетами формируют пары корреспондирующих позиций. Критерием, ограничивающим число таких пар, является общая сумма по дебету (кредиту) в документе.
- Результат сохраняется.
Сразу возникает несколько вопросов. Во-первых, что имеется в виду под словом документ в шаге 1. Ответ не столь очевиден. Часто одна хозяйственная операция приводит к автоматическому созданию нескольких FI документов. Примерами являются перемещения ТМЦ и ОС между заводами или балансовыми единицами (БЕ), оплаты открытых позиций из других БЕ, перевыставление расходов и т.д. Для такого рода операций в каждой БЕ создается отдельный FI документ, и всем созданным документам присваивается единый общий номер (поле BKPF-BVORG). Если балансовые единицы принадлежат одному юридическому лицу и мы хотим исключить 79 счет из определения корреспонденции, то необходимо группировать позиции дебетов и кредитов в шаге 1 по этому общему номеру, тем самым объединяя вместе логически связанные друг с другом первичные FI проводки.
Следующий вопрос касается интерпретации приоритетов в шаге 3. Если мы говорим, что «чем выше приоритет, тем более вероятна корреспонденции», то логично запретить отрицательные значения и интерпретировать приоритет равный 0, как запрет корреспонденции. Также следует зафиксировать некоторое максимально возможное значение приоритета (например, 1.000.000), соответствующее 100%-ой вероятности. Применение описанного выше алгоритма может привести к тому, что корреспонденция для части позиций документа останется неопределенной. Если таких документов немного, то они могут обрабатываться специальными более сложными алгоритмами (для чего может использоваться технология BAdI), либо анализироваться визуально бухгалтером, поскольку запрещенная корреспонденция в документе может свидетельствовать об ошибке, сделанной в момент проводки.
Вопрос к шагу 6: что следует сохранять? Дублирование всех полей основной и корреспондирующей позиций (уже имеющихся в базе данных) не выглядит разумным. Сохранять следует необходимый минимум информации, а именно ключевые поля (БЕ, номера документов и их позиций) и суммы. SAP BW on HANA позволяет эффективно строить OLAP отчетность на объектах соединенных операциями JOIN в композитных провайдерах и Calculation View. Тем самым, доступны абсолютно все поля из заголовков и позиций документов, что позволяет легко строить такие востребованные отчеты, как:
- оборотные ведомости по дебиторам и кредиторам с корреспонденцией счетов;
- анализ отклонений на 16 счетах в разрезе номеров материалов или основных средств, которые имеются в корреспондирующих позициях;
- анализ перевыставляемых расходов и расчетов между БЕ с исключением 79 счетов;
- разделение условных и фактических начислений расходов и доходов по корреспондирующим балансовым счетам и многие другие.
Техника Calculation View позволяет легко вводить в отчетность счета синтетического учета (например, первые 4 символа номера аналитического счета) без необходимости создания атрибутов навигации для признака 0GL_ACCOUNT, тем самым не усложняя стандартную структуру данных.
Реализация
В рамках архитектуры корпоративных хранилищ данных LSA++, разделяются уровни передачи данных (Data Propagation Layer) и витрин данных (Architected Data Mart Layer). Исходные данные финансовых документов хранятся в aDSO, принадлежащих первому уровню, результаты расчета корреспонденции должны сохраняться в aDSO, принадлежащем второму. Сам процесс расчета происходит в пользовательской программе (user routine) трансформации, связывающей эти два aDSO. Семантическое группирование позволяет разбить поток данных на пакеты таким образом, чтобы каждый документ попадал целиком в один пакет. В итоге получается, что кодирование алгоритма, описанного выше, требует менее 200 строк АВАР. Следует отметить, что этот код является абсолютно универсальным и переносимым. Механизм распараллеливания при запуске процесса переноса данных (DTP) позволяет поднять производительность в 10 и более раз, по сравнению с однопоточным выполнением, без каких-либо усилий со стороны разработчика. Звучит слишком просто, не правда ли? Где же спрятаны все сложные правила определения приоритетов для корреспондирующих позиций? В BRFplus функции, вызываемой в user routine трансформации на шаге 3 описанного выше алгоритма. Эта функция имеет два входящих параметра: анализируемые позиции по дебету и кредиту, и один исходящий – целочисленный «Приоритет» корреспонденции, как показано на Рис. 1:
Рис. 1. Параметры функции
Структуры CREDIT_ITEM и DEBIT_ITEM являются идентичными и содержат все поля из позиций и заголовков первичных FI документов.Тело функции состоит из одного или нескольких наборов правил, выполняемых в определенной последовательности, как показано на Рис. 2:
Рис.2. Наборы правил, составляющие тело функции.
В нашем случае определены 2 набора правил:
- TRANSFORM – в котором анализируемые позиции преобразуются к определенному стандартному виду, удобному для последующего анализа (что , естественно, не влияет на позиции самого исходного документа);
- SET_PRIORITY – где определяется приоритет корреспонденции.
«Набор правил» BRFplus состоит из последовательно выполняемых «правил», каждое из которых представляет собой простую логическую конструкцию IF-THEN-ELSE.Для того, чтобы проиллюстрировать описываемую технику настроек корреспонденции, не погружаясь слишком глубоко в детали, рассмотрим простой, но показательный пример - счет-фактуру дебитора, как показано в Таблице 1:
Таблица 1. Пример документа для разбора корреспонденции.
Как известно, код налога в позициях дебиторов и кредиторов проставляется только тогда, когда он уникален для документа. Мы можем стандартизовать представление удаляя код налога из этих позиций, как показано на Рис. 3:
Рис. 3. Пример правил, удаляющих код налога из позиций дебиторов и кредиторов.
Мы определили два похожих правила для позиций по дебету и кредиту, которые инициализируют «Код НДС», если «Вид счета» = «D» или «K».Перейдем к набору правил SET_PRIORITY, рассчитывающему приоритет корреспонденции. В его заголовке мы определяем две переменные (см. Рис. 4):
- «Запрет», имеющую булев тип и инициализируемую таблицей решений «Запрет корреспонденции».
- «Таблица приоритетов», являющуюся таблицей целых чисел. Первоначально эта таблица пуста.
Рис. 4. Определение набора правил, рассчитывающего приоритет корреспонденции.
Для нашего простого примера, запрещенные корреспонденции могут быть определены в таблице решений следующего вида, как показано на Рис. 5:
Рис. 5. Таблица решений, определяющая запрещенные корреспонденции.
Мы запрещаем корреспонденцию счета 90-03 «НДС при реализации» со всеми счетами, кроме 68-01 «Начисленный НДС». Однако, поскольку вместо номеров счетов используются внутренние коды операций, это правило будет действовать для всех счетов-фактур, неважно продается товар или, например, объект ОС.Тело набора правил SET_PRIORITY состоит из следующих трех правил, как показано на Рис. 6:
Рис. 6. Тело набора правил, определяющего приоритет корреспонденции.
- «Запрет = истинно» – это Exit-условие завершает выполнение функции, если переменная «Запрет» имеет значение «Истинно». В этом случае приоритет корреспонденции равен 0.
- «Сумма приоритетов» – это правило состоит из 2 шагов: сначала заполняется переменная «Таблица приоритетов» на основании таблицы решений «Приоритеты», затем приоритет корреспонденции вычисляется как сумма всех строк «Таблицы приоритетов».
- «Приоритет = 1» – это правило устанавливает приоритет корреспонденции равным 1, если предыдущее правило не смогло его определить для анализируемой пары позиций.
Таблица решений «Приоритеты», для нашего примера, имеет вид, как показано на Рис. 7:
Рис. 7. Таблица решений «Приоритеты».
Также, как и в предыдущем примере, мы можем не задавать номера счетов. Каждая строка таблицы определяет приоритет корреспонденции, если выполняется заданное в ней условие. Рассмотрим эти условия построчно:
- Позиции с кодами ZUD и MWS получают наивысший приоритет 1000.
- Аналогично строке 1, но дебет и кредит меняются местами.
- Если «Код НДС» в обоих позициях совпадает, приоритет будет увеличен на 200. Это позволяет правильно определить корреспонденцию для документов с несколькими кодами НДС.
- Если суммы в обоих позициях совпадают, приоритет будет увеличен на 100. Это правило является общим – позиции с совпадающими суммами имеют большую вероятность корреспондировать.
Таким образом, мы определяем корреспонденцию позиций для счетов 90-03 и 68-01 с совпадающими кодами НДС как наиболее приоритетную. После чего в документе остается единственная позиция по дебету (счет 62-01) и несколько по кредиту (счет 90-01). Следовательно, дальнейшая корреспонденция определяется однозначно.
Данный пример является чисто иллюстративным. Реальные правила для определения корреспонденции являются гораздо более сложными. Однако, возможности моделирования BRFplus позволяют структурировать эти правила удобным образом, выделяя разные типы хозяйственных операций в отдельные таблицы решений, каждая из которых может иметь свой набор столбцов-условий.
Таким образом, создается функция, рассчитывающая приоритеты корреспонденции для пар позиций по дебету и кредиту. В момент первого выполнения, сконфигурированные правила компилируются в исполняемый АВАР код, что позволяет добиться наивысшей возможной производительности.
Данный пример является чисто иллюстративным. Реальные правила для определения корреспонденции являются гораздо более сложными. Однако, возможности моделирования BRFplus позволяют структурировать эти правила удобным образом, выделяя разные типы хозяйственных операций в отдельные таблицы решений, каждая из которых может иметь свой набор столбцов-условий.
Таким образом, создается функция, рассчитывающая приоритеты корреспонденции для пар позиций по дебету и кредиту. В момент первого выполнения, сконфигурированные правила компилируются в исполняемый АВАР код, что позволяет добиться наивысшей возможной производительности.
Заключение
Описанная в статье реализация OLAP отчетности по корреспонденции счетов позволяет совершить качественный рывок в этой важной теме, используя возможности SAP BW on HANA. Остается, однако, ряд вопросов, которые требуют дополнительного обсуждения:
- Данные в BW обычно загружаются периодически, что делает отчетность актуальной на конец предыдущего дня (если загрузка происходит, как обычно раз, в сутки). Если актуальность данных является критически важной, то можно использовать любую из известных технологий BW отчетности в режиме «реального времени», предлагаемых SAP.
- Описанный в статье алгоритм является эвристическим и требует тщательной настройки правил определения приоритетов корреспондирующих позиций. К сожалению, никаких «теоретических» принципов здесь нет, и процесс настройки быстро превращается в «шаманство». Однако, основным достоинством этого алгоритма является сравнительная простота и, как следствие, возможность эффективной реализации. Попытки усложнения и усовершенствования не приводят к существенным улучшениям, одновременно серьезно ухудшая производительность. Время выполнения для описанного алгоритма квадратично зависит от числа позиций в документе, что, для данной задачи, является наилучшим возможным результатом.
- Возникает вопрос можно ли реализовать описанную в статье функциональность полностью на сервере базы данных HANA без использования АВАР. Принципиальный ответ – да. Таблицы решений BRFplus могут быть транслированы в HANA артефакты при помощи Decision Service Management (DSM), представляющего собой Add-on к BRFplus. Однако, для полноценной оптимизации потребуется программирование на L, внутреннем языке БД HANA, недоступном для партнеров и клиентов SAP. Логика, легко реализуемая в АВАР коде, теряет свою гибкость и универсальность, будучи перенесена в SQLScript, при этом, конечный выигрыш в производительности отнюдь не очевиден. Однако, SAP анонсировал продолжение работ по интеграции BRFplus и HANA Rules Framework (HANA HRF), поэтому, возможно, в недалеком будущем, BRFplus будет предоставлять такие же возможности моделирования при работе с HANA, какие, в настоящий момент, имеются для АВАР сервера приложений.