
/BACK
Introduction to the problem
"Correspondence of accounts is a system of accounting in which each transaction is recorded by the identical amount in two accounts: the debit of one and the credit of the other," according to the Dictionary of Economic Terms. With such a narrow meaning of the phrase, it is clear that SAP does not support "Correspondence of Accounts." The FI module's Document idea offers a lot of flexibility, which is especially crucial for creating automated transactions. Other dictionaries, on the other hand, provide a less rigorous reading. "Correspondence of Accounts is the relationship between bookkeeping accounts when reporting a business transaction utilizing the double entry technique," according to a Large Encyclopedic Dictionary. With such a "lightweight" approach, the effort is simplified to breaking each FI document into pairs of corresponding positions. This approach has been used in a number of well-known applications, the most well-known of which is included in the Russian localization. All of these applications are integrated into an ERP system, which poses the following issues:
- significant load on the ERP application server;
- reports have a fixed format, each report is a separate ABAP program;
- setting up correspondence rules takes considerable effort, since it is based on the standard technique of tuning tables.
Solving the problem
This article proposes an alternate method that avoids the aforementioned drawbacks. It is suggested to move the correspondence calculation and all related reports to SAP BW. Really,
- Standard extraction replicates FI documents in BW storage, and the main work on correspondence calculation is done as part of the usual data transformation process, which completely unloads the ERP server;
- The standard OLAP toolkit makes it simple to create reports of almost any complexity, with powerful navigation and data filtering tools;
- Business Rules Framework Plus (BRFplus) technology eliminates the need for setup tables entirely and provides an added benefit in the shape of high performance, since the preset rules for determining correspondence are immediately converted into executable ABAP code.
Solution algorithm
So, "looking" at the accounting document stored in the FI module, it is necessary to dismantle it into pairs of corresponding positions. By the way, this is a standard artificial intelligence task. We will not, however, give sophisticated or exotic solutions, instead opting for a tried-and-true simple heuristic approach consisting of the following six steps:
- The debit and credit document locations are divided into two tables, Td and Tc.
- A table of all theoretically possible correspondences is constructed (the result of the Td and Tc tables);
- Any possible correspondence is examined, and an integer weight is assigned to it as a consequence (priority). The greater the priority, the more likely the correspondence. Any fields from the document's title and FI positions can be utilized to compute priority.
- The table of probable correspondence is arranged by priority in descending order.
- The highest-priority rows create a pair of corresponding positions. The condition that limits the number of such pairings is the total amount of the debit (credit) in the document.
- The result is saved.
Several questions arise right away. First, let's define what the term "document" in step 1 means. The solution isn't that clear. Several FI documents are frequently created automatically as a result of a single business action. Movement of commodities and equipment between factories or balance sheet units (BE), payment of open positions from other BE, re-presentation of expenditures, and so on are examples. In each BE, a distinct FI document is produced for these activities, and all created documents are given the same number (the BKPF-BVORG field). If the balance sheet units all belong to the same legal organization, and we wish to remove account 79 from the definition of correspondence, we must group the debit and credit positions in step 1 by this common number, resulting in logically linked main FI transactions being combined.
The following issue pertains to the interpretation of priority in step 3. If we claim that "the greater the priority, the more likely correspondence is," it makes sense to prohibit negative values and interpret a priority of 0 as a correspondence prohibition. You should also provide a maximum potential priority value (for example, 1.000.000) that corresponds to a likelihood of 100 percent. The use of the algorithm described above may result in the undefined correspondence for certain of the document components. If there are only a few of these documents, they can be evaluated using more advanced algorithms (for which BAdI technology can be employed) or visually reviewed by an accountant, because forbidden correspondence in the document could signal a posting error.
Step 6: What should be saved? It doesn't seem acceptable to duplicate all of the fields of the main and corresponding positions (which are already in the database). The bare minimum of information should be kept, notably the important fields (BE, document numbers and their positions) and values. SAP BW on HANA enables you to quickly create OLAP reporting on items linked by composite providers and Calculation View via JOIN procedures. As a result, all fields from document titles to positions are available, making it simple to create popular reports like:
- current debtor and creditor statements with correspondence of accounts;
- analysis of deviations on 16 accounts in the context of numbers of materials or fixed assets that are available in corresponding positions;
- analysis of the re-presented expenses and settlements between BE with the exception of 79 accounts;
- separation of conditional and actual accruals of expenses and income on corresponding balance sheet accounts and many others.
The Calculation View approach makes it simple to input synthetic accounting accounts into reporting (for example, the first four characters of the analytical account number) without having to build navigation characteristics for the 0GL ACCOUNT attribute, simplifying the data structure.
Implementation
Data Propagation Layer and Architectural Data Mart Layer are separated in the LSA++ corporate data storage architecture. The basic data of financial documents should be saved in the aDSO of the first level, while the results of correspondence calculation should be recorded in the aDSO of the second level. The computation is done in a user transformation program (user procedure) that connects these two aDSOs. Semantic grouping allows you to divide the data stream into packages, with each document belonging to just one of them. As a consequence, encoding the procedure described above only necessitates fewer than 200 lines of ABAP. It is important to point out that this code is completely universal and portable. When compared to single-threaded execution, the parallelization mechanism at the start of the data transfer process (DTP) allows you to enhance performance by 10 or more times without any effort on the developer's side. Doesn't it seem a little too simple? Where are all the intricate rules for assigning priority to corresponding positions hidden? They are hidden in step 3 of the algorithm: the BRFplus function which is performed in the user transformation routine. This function has two incoming parameters: the analyzed debit and credit positions, and one outgoing parameter: the integer "Priority" of correspondence, as shown in Fig. 1.:
Fig. 1. Function Parameters
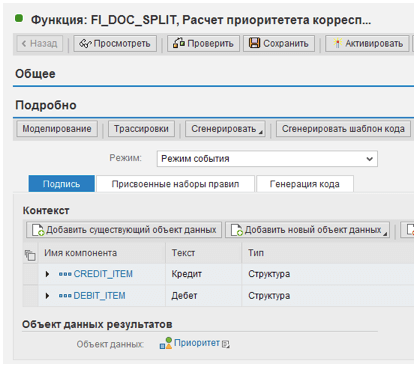
The CREDIT ITEM and DEBIT ITEM structures are identical, containing all information from the principal FI documents' locations and headers. As illustrated in Figure 2, the function's body is made up of one or more sets of rules that are performed in a certain order.
Figure 2: The sets of rules that comprise the function's body.
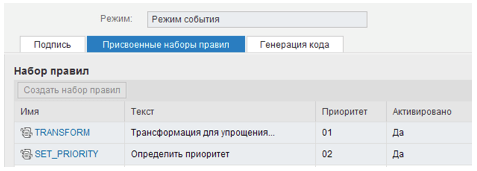
Two sets of rules are defined in our case:
- TRANSFORM in which the examined positions are changed to a standard format that may be used for further analysis (without affecting the positions of the source document);
- SET PRIORITY determines the priority of correspondence.
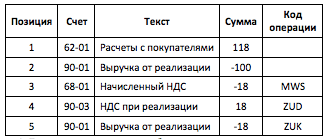
Each "rule" in the BRFplus "rule set" is a basic logical IF-THEN-ELSE construct that is performed in order. Let us examine a basic but illustrative example - the debtor's invoice, as given in Table 1 - to illustrate the suggested approach of correspondence settings without diving too deeply into the intricacies.
Table 1. An example of a document that may be used to analyze correspondence.
As you may be aware, the tax code in debtor and creditor positions is only recorded when it is unique to the document. Figure 3 shows how we may standardize the appearance by deleting the tax code from these items.
Fig. 3. Example of rules that remove the tax code from the positions of debtors and creditors.
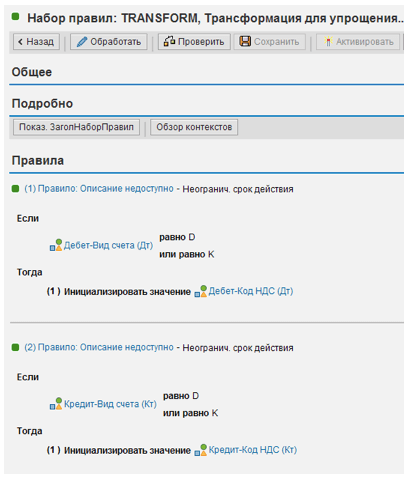
We have established two comparable rules for debit and credit items that initialize the "VAT Code" if the "Account Type" is "D" or "K."
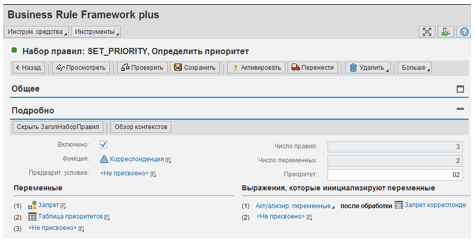
Let's move on to the SET_PRIORITY rule set, which determines correspondence priority. We define two variables in its header (see Fig. 4):
- "Ban", which has a Boolean type and is initialized by the decision table "Ban correspondence".
- "Priority table", which is a table of integers. Initially, this table is empty.
Fig. 4. Defining a set of rules that calculates the priority of correspondence.
For our simple example, forbidden correspondences can be defined in a solution table of the following type, as shown in Fig. 5:
Fig. 5. A solution table defining prohibited correspondence.
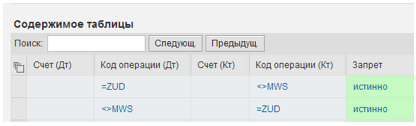
All invoices except 68-01 "Accrued VAT" are not allowed to correspond with invoice 90-03 "VAT on sale." However, because internal transaction codes are used instead of account numbers, this restriction applies to all bills, regardless of whether the product is sold or an OS object, for example. The following three rules make up the body of the SET PRIORITY rule set, as seen in Figure 6:
Fig. 6. The body of a set of rules that determines the priority of correspondence.
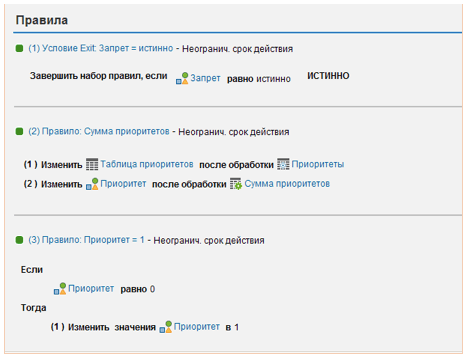
- "Prohibition = true" is an Exit condition that terminates the execution of the function if the variable "Prohibition" has the value "True". In this case, the priority of correspondence is 0.
- "Sum of priorities". This rule consists of 2 steps: first, the variable "Priority Table" is filled in based on the solution table "Priorities", then the priority of correspondence is calculated as the sum of all the rows of the "Priority Table".
- "Priority = 1". This rule sets the priority of correspondence equal to 1, if the previous rule could not determine it for the analyzed pair of positions.
For our case, the solution table "Priorities" is presented in Fig. 7:
Fig. 7. "Priorities" solution table.
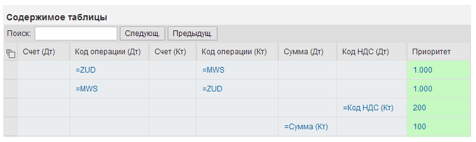
We can also leave the account numbers blank, as in the preceding case. If the criterion provided in each row of the table is satisfied, that row determines the priority of correspondence. Let's have a look at these circumstances one by one:
- Positions with ZUD and MWS codes receive the highest priority of 1000.
- Similar to line 1, but debit and credit are swapped.
- If the "VAT Code" in both items matches, the priority will be increased by 200. This allows you to correctly identify correspondence for documents with multiple VAT codes.
- If the amounts in both positions match, the priority will be increased by 100. This rule is general – positions with matching amounts are more likely to correspond.
Thus, we define the correspondence of items for accounts 90-03 and 68-01 with matching VAT codes as the highest priority. After that, a single debit position (account 62-01) and several credit positions (account 90-01) remain in the document. Consequently, further correspondence is determined unambiguously. This is only a hypothetical scenario. The rules for determining correspondence are considerably more complicated. The BRFplus modeling features, on the other hand, enable you to organize these rules in a practical manner, dividing different sorts of business activities into independent solution tables, each with its own set of condition columns.
As a result, a function for calculating correspondence priority for pairs of debit and credit positions is built. The configured rules are compiled into executable ABAP code on the initial run, allowing you to get the best potential performance.
As a result, a function for calculating correspondence priority for pairs of debit and credit positions is built. The configured rules are compiled into executable ABAP code on the initial run, allowing you to get the best potential performance.
Conclusion
The application of OLAP reporting on account correspondence detailed in this article enables you to achieve a qualitative breakthrough in this key area by leveraging SAP BW on HANA capabilities. However, there are a few difficulties that need to be addressed further:
- Data in BW is often downloaded on a regular basis, therefore reporting is only relevant at the end of the previous day (if the download occurs, as usual, once a day). If data timeliness is crucial, you can utilize any of SAP's well-known "real-time" BW reporting solutions.
- The algorithm presented in the article is heuristic, and therefore necessitates careful tuning of the principles for establishing related position priority. Unfortunately, there are no "theoretical" concepts to be found here, and tuning rapidly devolves into "shamanism." The fundamental advantage of this method, however, is its relative simplicity and, as a result, its ability to be implemented effectively. Attempts to complicate and improve do not result in substantial gains while severely reducing performance. The provided algorithm's execution time is proportional to the number of positions in the document, which is the best possible outcome for this task.
- The issue arises as to whether the functionality described in the article can be implemented entirely on the HANA database server without the use of ABAP. Yes, in the most basic sense. Decision Service Management (DSM), an Add-on to BRFplus, can transform BRFplus solution tables into HANA objects. Full optimization, on the other hand, will necessitate programming in L, the HANA database's internal language, which SAP partners and customers do not have access to. When logic, which is readily implemented in ABAP code, is transferred to SQLScript, it loses its flexibility and variety, and the end performance improvement is marginal. However, SAP said that development on the integration of BRFplus and HANA Rules Framework (HANA HRF) will continue, so BRFplus may soon provide the same modeling capabilities for HANA as it does for ABAP application servers.
/BACK
Introduction to the problem
"Correspondence of accounts is a system of accounting in which each transaction is recorded by the identical amount in two accounts: the debit of one and the credit of the other," according to the Dictionary of Economic Terms. With such a narrow meaning of the phrase, it is clear that SAP does not support "Correspondence of Accounts." The FI module's Document idea offers a lot of flexibility, which is especially crucial for creating automated transactions. Other dictionaries, on the other hand, provide a less rigorous reading. "Correspondence of Accounts is the relationship between bookkeeping accounts when reporting a business transaction utilizing the double entry technique," according to a Large Encyclopedic Dictionary. With such a "lightweight" approach, the effort is simplified to breaking each FI document into pairs of corresponding positions. This approach has been used in a number of well-known applications, the most well-known of which is included in the Russian localization. All of these applications are integrated into an ERP system, which poses the following issues:
- significant load on the ERP application server;
- reports have a fixed format, each report is a separate ABAP program;
- setting up correspondence rules takes considerable effort, since it is based on the standard technique of tuning tables.
Solving the problem
This article proposes an alternate method that avoids the aforementioned drawbacks. It is suggested to move the correspondence calculation and all related reports to SAP BW. Really,
- Standard extraction replicates FI documents in BW storage, and the main work on correspondence calculation is done as part of the usual data transformation process, which completely unloads the ERP server;
- The standard OLAP toolkit makes it simple to create reports of almost any complexity, with powerful navigation and data filtering tools;
- Business Rules Framework Plus (BRFplus) technology eliminates the need for setup tables entirely and provides an added benefit in the shape of high performance, since the preset rules for determining correspondence are immediately converted into executable ABAP code.
Solution algorithm
So, "looking" at the accounting document stored in the FI module, it is necessary to dismantle it into pairs of corresponding positions. By the way, this is a standard artificial intelligence task. We will not, however, give sophisticated or exotic solutions, instead opting for a tried-and-true simple heuristic approach consisting of the following six steps:
- The debit and credit document locations are divided into two tables, Td and Tc.
- A table of all theoretically possible correspondences is constructed (the result of the Td and Tc tables);
- Any possible correspondence is examined, and an integer weight is assigned to it as a consequence (priority). The greater the priority, the more likely the correspondence. Any fields from the document's title and FI positions can be utilized to compute priority.
- The table of probable correspondence is arranged by priority in descending order.
- The highest-priority rows create a pair of corresponding positions. The condition that limits the number of such pairings is the total amount of the debit (credit) in the document.
- The result is saved.
Several questions arise right away. First, let's define what the term "document" in step 1 means. The solution isn't that clear. Several FI documents are frequently created automatically as a result of a single business action. Movement of commodities and equipment between factories or balance sheet units (BE), payment of open positions from other BE, re-presentation of expenditures, and so on are examples. In each BE, a distinct FI document is produced for these activities, and all created documents are given the same number (the BKPF-BVORG field). If the balance sheet units all belong to the same legal organization, and we wish to remove account 79 from the definition of correspondence, we must group the debit and credit positions in step 1 by this common number, resulting in logically linked main FI transactions being combined.
The following issue pertains to the interpretation of priority in step 3. If we claim that "the greater the priority, the more likely correspondence is," it makes sense to prohibit negative values and interpret a priority of 0 as a correspondence prohibition. You should also provide a maximum potential priority value (for example, 1.000.000) that corresponds to a likelihood of 100 percent. The use of the algorithm described above may result in the undefined correspondence for certain of the document components. If there are only a few of these documents, they can be evaluated using more advanced algorithms (for which BAdI technology can be employed) or visually reviewed by an accountant, because forbidden correspondence in the document could signal a posting error.
Step 6: What should be saved? It doesn't seem acceptable to duplicate all of the fields of the main and corresponding positions (which are already in the database). The bare minimum of information should be kept, notably the important fields (BE, document numbers and their positions) and values. SAP BW on HANA enables you to quickly create OLAP reporting on items linked by composite providers and Calculation View via JOIN procedures. As a result, all fields from document titles to positions are available, making it simple to create popular reports like:
- current debtor and creditor statements with correspondence of accounts;
- analysis of deviations on 16 accounts in the context of numbers of materials or fixed assets that are available in corresponding positions;
- analysis of the re-presented expenses and settlements between BE with the exception of 79 accounts;
- separation of conditional and actual accruals of expenses and income on corresponding balance sheet accounts and many others.
The Calculation View approach makes it simple to input synthetic accounting accounts into reporting (for example, the first four characters of the analytical account number) without having to build navigation characteristics for the 0GL ACCOUNT attribute, simplifying the data structure.
Implementation
Data Propagation Layer and Architectural Data Mart Layer are separated in the LSA++ corporate data storage architecture. The basic data of financial documents should be saved in the aDSO of the first level, while the results of correspondence calculation should be recorded in the aDSO of the second level. The computation is done in a user transformation program (user procedure) that connects these two aDSOs. Semantic grouping allows you to divide the data stream into packages, with each document belonging to just one of them. As a consequence, encoding the procedure described above only necessitates fewer than 200 lines of ABAP. It is important to point out that this code is completely universal and portable. When compared to single-threaded execution, the parallelization mechanism at the start of the data transfer process (DTP) allows you to enhance performance by 10 or more times without any effort on the developer's side. Doesn't it seem a little too simple? Where are all the intricate rules for assigning priority to corresponding positions hidden? They are hidden in step 3 of the algorithm: the BRFplus function which is performed in the user transformation routine. This function has two incoming parameters: the analyzed debit and credit positions, and one outgoing parameter: the integer "Priority" of correspondence, as shown in Fig. 1.:
Fig. 1. Function Parameters
The CREDIT ITEM and DEBIT ITEM structures are identical, containing all information from the principal FI documents' locations and headers. As illustrated in Figure 2, the function's body is made up of one or more sets of rules that are performed in a certain order.
Figure 2: The sets of rules that comprise the function's body.
Two sets of rules are defined in our case:
- TRANSFORM in which the examined positions are changed to a standard format that may be used for further analysis (without affecting the positions of the source document);
- SET PRIORITY determines the priority of correspondence.
Each "rule" in the BRFplus "rule set" is a basic logical IF-THEN-ELSE construct that is performed in order. Let us examine a basic but illustrative example - the debtor's invoice, as given in Table 1 - to illustrate the suggested approach of correspondence settings without diving too deeply into the intricacies.
Table 1. An example of a document that may be used to analyze correspondence.
As you may be aware, the tax code in debtor and creditor positions is only recorded when it is unique to the document. Figure 3 shows how we may standardize the appearance by deleting the tax code from these items.
Fig. 3. Example of rules that remove the tax code from the positions of debtors and creditors.
We have established two comparable rules for debit and credit items that initialize the "VAT Code" if the "Account Type" is "D" or "K."
Let's move on to the SET_PRIORITY rule set, which determines correspondence priority. We define two variables in its header (see Fig. 4):
- "Ban", which has a Boolean type and is initialized by the decision table "Ban correspondence".
- "Priority table", which is a table of integers. Initially, this table is empty.
Fig. 4. Defining a set of rules that calculates the priority of correspondence.
For our simple example, forbidden correspondences can be defined in a solution table of the following type, as shown in Fig. 5:
Fig. 5. A solution table defining prohibited correspondence.
All invoices except 68-01 "Accrued VAT" are not allowed to correspond with invoice 90-03 "VAT on sale." However, because internal transaction codes are used instead of account numbers, this restriction applies to all bills, regardless of whether the product is sold or an OS object, for example. The following three rules make up the body of the SET PRIORITY rule set, as seen in Figure 6:
Fig. 6. The body of a set of rules that determines the priority of correspondence.
- "Prohibition = true" is an Exit condition that terminates the execution of the function if the variable "Prohibition" has the value "True". In this case, the priority of correspondence is 0.
- "Sum of priorities". This rule consists of 2 steps: first, the variable "Priority Table" is filled in based on the solution table "Priorities", then the priority of correspondence is calculated as the sum of all the rows of the "Priority Table".
- "Priority = 1". This rule sets the priority of correspondence equal to 1, if the previous rule could not determine it for the analyzed pair of positions.
For our case, the solution table "Priorities" is presented in Fig. 7:
Fig. 7. "Priorities" solution table.
We can also leave the account numbers blank, as in the preceding case. If the criterion provided in each row of the table is satisfied, that row determines the priority of correspondence. Let's have a look at these circumstances one by one:
- Positions with ZUD and MWS codes receive the highest priority of 1000.
- Similar to line 1, but debit and credit are swapped.
- If the "VAT Code" in both items matches, the priority will be increased by 200. This allows you to correctly identify correspondence for documents with multiple VAT codes.
- If the amounts in both positions match, the priority will be increased by 100. This rule is general – positions with matching amounts are more likely to correspond.
Thus, we define the correspondence of items for accounts 90-03 and 68-01 with matching VAT codes as the highest priority. After that, a single debit position (account 62-01) and several credit positions (account 90-01) remain in the document. Consequently, further correspondence is determined unambiguously. This is only a hypothetical scenario. The rules for determining correspondence are considerably more complicated. The BRFplus modeling features, on the other hand, enable you to organize these rules in a practical manner, dividing different sorts of business activities into independent solution tables, each with its own set of condition columns.
As a result, a function for calculating correspondence priority for pairs of debit and credit positions is built. The configured rules are compiled into executable ABAP code on the initial run, allowing you to get the best potential performance.
As a result, a function for calculating correspondence priority for pairs of debit and credit positions is built. The configured rules are compiled into executable ABAP code on the initial run, allowing you to get the best potential performance.
Conclusion
The application of OLAP reporting on account correspondence detailed in this article enables you to achieve a qualitative breakthrough in this key area by leveraging SAP BW on HANA capabilities. However, there are a few difficulties that need to be addressed further:
- Data in BW is often downloaded on a regular basis, therefore reporting is only relevant at the end of the previous day (if the download occurs, as usual, once a day). If data timeliness is crucial, you can utilize any of SAP's well-known "real-time" BW reporting solutions.
- The algorithm presented in the article is heuristic, and therefore necessitates careful tuning of the principles for establishing related position priority. Unfortunately, there are no "theoretical" concepts to be found here, and tuning rapidly devolves into "shamanism." The fundamental advantage of this method, however, is its relative simplicity and, as a result, its ability to be implemented effectively. Attempts to complicate and improve do not result in substantial gains while severely reducing performance. The provided algorithm's execution time is proportional to the number of positions in the document, which is the best possible outcome for this task.
- The issue arises as to whether the functionality described in the article can be implemented entirely on the HANA database server without the use of ABAP. Yes, in the most basic sense. Decision Service Management (DSM), an Add-on to BRFplus, can transform BRFplus solution tables into HANA objects. Full optimization, on the other hand, will necessitate programming in L, the HANA database's internal language, which SAP partners and customers do not have access to. When logic, which is readily implemented in ABAP code, is transferred to SQLScript, it loses its flexibility and variety, and the end performance improvement is marginal. However, SAP said that development on the integration of BRFplus and HANA Rules Framework (HANA HRF) will continue, so BRFplus may soon provide the same modeling capabilities for HANA as it does for ABAP application servers.